(一)初识Linux
前言:我为什么要学Linux?
- 国内墙太厚,打算买vps自己建服务器,想学到更多知识
- 想体验不同系统的操作
- 为了更深次的理解计算机
- 看《30天自制操作系统》感觉自己基础不行,停留在第8天,并且前面的知识也很迷糊(虽然这本书是针对小白的,恕我比小白还白吧:<),想制作一个小系统,也算对大一的自己一个目标吧
历史
- 1969年贝尔实验室的Ken Thompson使用汇编写了
Unics系统,提出了两个重要概念- 所有程序或系统设备都是文件
- 不管程序本身还是附属文件,所写的程序只有一个目的,且要有效地完成目标
- 1973年Dennis Ritchie使用
C语言将Unics重新编译,并命名为UNIX(一开始并没有得到重视,源码可以被拿来做学术研究) - 1977年Bill Joy发布了BSD(Berkeley Software Distribution),因为使用了UNIK源码,被称为UNIK-like系统
- 1979年AT&T想收回了UNIX的版权,在发行第七版时,特别声明“不可向学生提供源码”,因为版权问题造成了许多商业纠纷
- 1984年Andrew S.Tanenbaum为了教学生认识UNIX,不参考UNIX源码编写了
Minix,能与UNIX兼容 - 1984年Richard Stallman提倡
GNU计划,倡导自由软件(free software),强调软件可以自由的取得,复制,修改再发行,并规范GPL授权模式,GPL的软件不可单纯的仅销售其软件,也不可修改软件授权 - 1991年芬兰人Linus Torvalds开发出
Linux系统,他的成功离不开Minix(UNIX)、GNU、internet、POSIX及虚拟团队的产生 - Linux本身是个普通的操作系统,开发网站是https://www.kernel.org,我们称他的底层数据为内核
- 可以查询Linux的内核版本是否长期维护
- Linux的发行版组成:Linux内核+自由软件+文档(工具)+可完全安装的程序
硬盘分区
在Linux系统中,每个设备都被当成一个文件来对待,比如SATA为
/dev/sd[a-d](按读取顺序命名)
为什么要分区?
可以保护数据
比如C盘装系统,D盘装应用
高效的性能
当某一数据来自某一分区时,系统会锁定该分区
MBR(MS-DOS)分区表格式与限制
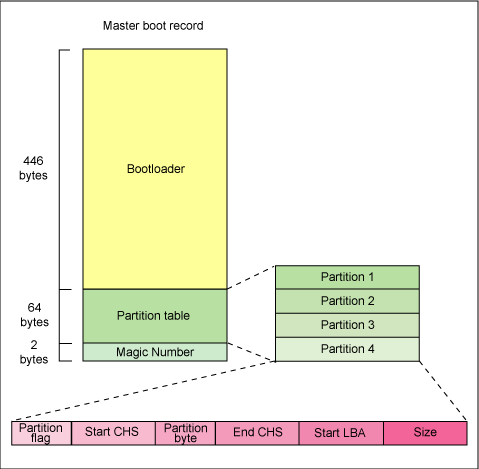
早期Linux为了兼容Windows磁盘,采用了MBR(
Master Boot record,主引导记录)来处理引导程序和分区表在旧磁盘第一个扇区的512字节里主要含有两个信息:
- MBR:可以安装启动引导程序的地方,有446字节
- 分区表(
partition table):64字节(参考https://blog.csdn.net/White_Idiot/article/details/80088115)
由于一组记录区有16字节,所以只能有4组记录表,每组 记录表记录了该区段的起始和结束的柱面号码
假设上面的设备为
/dev/sda/,P1就是/dev/sda1
四组分区记录被称为主要(Primary)或扩展(Extended)分区
- 其实分区只是修改那64字节
- 最小单位通常叫柱面(
Cylinder) - 系统写入磁盘时一定要参考分区表
扩展分区的目的是使用额外的扇区来记录分区信息,扩展分区不能被格式化 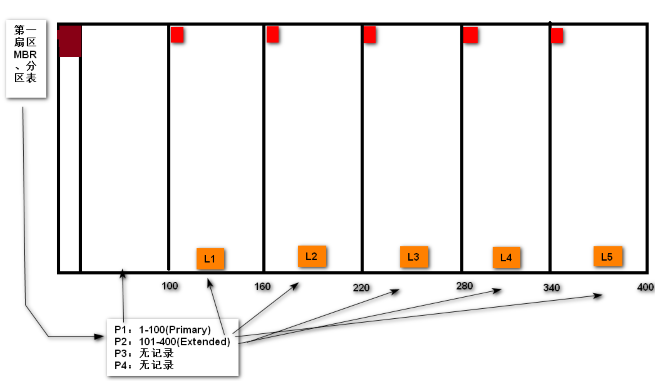
- 由扩展分区切出来的5个分区就是逻辑分区(
logical partition),原理有点复杂 - 上图的设备文件名如下:
- P1:/dev/sda1
- P2:/dev/sda2
- L1:/dev/sda5
- L2:/dev/sda6
- L3:/dev/sda7
- L4:/dev/sda8
- L5:/dev/sda9
- 所以,1-4的文件名是留给主分区的,这是MBR的特性,其他特性
- P+E的数量只能有4个
- 扩展分区只能有1个
- 逻辑分区是扩展分区划分出来的
- 能被格式化的只有P、L
- 逻辑分区的数量要看操作系统,Linux已经突破了63个的限制
另外,需要注意的是不同类型的分区不能合并,比如E和L,合并的话分区表被破坏,所有逻辑分区会被删除
由于第一扇区记录了分区表,若它损坏了,emmm硬盘就废了
- 由于记录每组分区的只有16字节,所有MBR有很多限制
- 无法使用2.2TB以上的硬盘
- 仅有一个区块,损坏后很难修复
- 引导区块只有446字节,无法存储较多的程序代码
GPT(GUID partition table)磁盘分区表
为了扩大容量,现在每个扇区已经到4K大小,为了兼容所有磁盘,GPT使用了LBA(
Logical Block Address,逻辑块地址)处理,默认512字节大小,从LBA0开始编号
与MBR不同,GPT使用了34个LBA区块记录分区信息,磁盘的最后34个LBA区块也拿来做备份,更加安全
LBA0
也有两部分,一是和MBR相似的446字节,存储了第一阶段的引导程序;二是64字节放的是特殊标志符,表示这是GPT格式(程序如果不懂就不会处理,更加安全)
LBA1(GPT表头记录)
记录了分区表本身的位置和大小,也记录了备份的位置,放置了分区表校验码(CRC32),如果有错就去找备份
LBA2-33(实际记录分区信息处)
从2开始,每个LBA都记录了4组分区信息,在默认的模式下,可以有128组分区记录
因为有512字节,4组记录分区信息,所以用了128字节记录每组信息,此外每组还用了64位来记录记载开始/结束的号码
于是单元分区最大限制在2^64 x 512B = 2^30TB,emm大到爆炸
也就是说GPT每组分区都可以单独存在,每组都可以格式化
BIOS和UEFI启动检测程序
并不是所有的操作系统都能读取GPT的格式,也不是所有的“硬件(盘?)”都支持GPT格式,是否能读写又与启动检测程序有关
BIOS搭配MBR/GPT启动流程
- BIOS:启动主动执行的固件,认识第一个可启动的设备
- MBR:第一个启动设备的第一个扇区的主引导记录块,里面有启动引导代码
- 启动引导程序(boot loader):一个可读取内核文件来执行的软件
- 内核文件:启动OS
如果引导程序支持GPT,也会启动GPT里的系统
另外,BIOS和MBR是硬件本身都会支持的功能,boot loader则是安装在MBR上的一个软件
boot loader的功能:
- 提供选项:可以选择不同的启动选项,这是多重引导的重要功能
- 加载内核文件:直接指向可使用的程序区段启动OS
- 转交给其他boot loader
这意味着计算机可以有两个以上的boot loader,启动区除了可以安装在MBR以外,还可以安装在每个分区的启动扇区(boot sector),代表可以多重引导
为什么安装多重引导要先安装windows再安装Linux?
- Linux安装时,可以手动选择将boot loader安装在MBR还是别的分区的启动扇区,而且Linux的引导程序可以手动选择,所以可以将windows的启动装在Linux的启动引导程序里
- 而Windows在安装时,会覆盖安装的分区的MBR或启动扇区,不能选择
UEFI BIOS搭配GPT启动流程
因为BIOS是16位程序,与新系统有点不搭,所以有了UEFI(Unified Extensible Firmware Interface,同一可扩展固件接口)
| 传统BIOS | UEFI | |
|---|---|---|
| 程序语言 | 汇编 | C |
| 硬件资源控制 | 使用IRQ处理,不可变的内存存取,不可变的输入/输出存取 | 使用驱动程序与协议 |
| 处理器运行环境 | 16位 | CPU保护模式 |
| 扩充方式 | 通过IRQ连接 | 直接加载驱动程序 |
| 第三方厂商支持 | 较差 | 较且可支持多平台 |
| 图形能力 | 较差 | 较佳 |
| 内置简化操作系统环境 | 不支持 | 支持 |
目录树
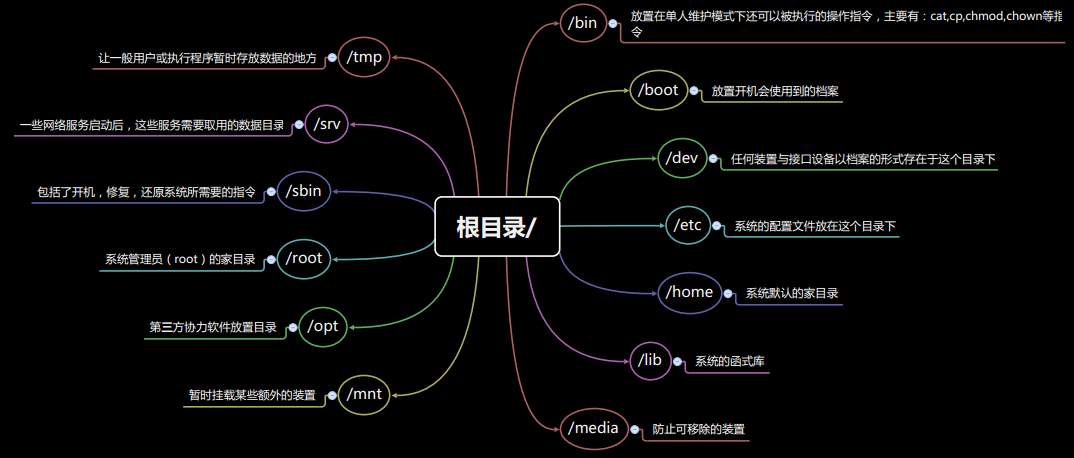
文件系统挂载到目录树上
挂载就是利用一个目录当成进入点,将磁盘分区的信息放在该目录下,进入这个目录就知道了这个分区的信息