3.传输层
本章详细的介绍了运输层的TCP和UDP协议
3.1-概述运输层服务
运输层对不同主机之间的应用程序提供了逻辑通信(logic communication),类似将应用层连在了一起。
运输层协议实在端系统中实现的,运输层通过应用层接收到的报文转换为运输层分组,该分组被称为报文段(segment),然后交给网络层被封装成网络层分组(数据报) 向目的地发送。
3.1.1-运输层和网络层的关系
网络层为主机之间提供逻辑通信,运输层为主机的应用程序提供逻辑通信。
3.1.2-运输层概述
提供了两个协议:
- UDP(用户数据报协议):提供不可靠的,无连接的服务
- TCP(传输控制协议):提供可靠的,面向连接的服务
当我们设计应用程序时,必须选择其中一个协议(才能生成套接字)。
为了理解这两个协议,先说一下网络层的IP,IP的服务是尽力而为交付服务(best-effort delivery service),它不保证报文段的交付、顺序交付及完整性,所以被称为不可靠服务(unreliable service),每个主机都有一个IP地址。
而UDP和TCP则是将两个端系统的IP对话服务扩展到进程之间的对话。
3.2多路复用和多路分解
当运输层报文到达运输层时,运输层检查这些字段,得到套接字(唯一标识的),然后将数据传给这个套接字,这些工作被称为多路分解(demultiplexing)。
在源主机收集数据块封装首部信息,生成报文段传给网络层,这些工作被称为多路复用(multipexing)。
所以多路复用要求:
- 套接字有唯一标识符
- 有特殊字段来指示对话的套接字(如源端口和目标端口)
注意0-1023端口是比较特殊的,如80给了HTTP,25给了SMTP…详细请看RFC1700
1.无连接的多路复用和多路分解
使用python创建一个UDP套接字来分析
1 | clientSocket = socket(socket.AF_INET,socket.SOCK_DFRAM) |
这种方式创建的socket在运输层会自动被分配一个1024-65535的端口,并且该端口未被主机使用,也可以使用bind()方法指定端口
1 | clientSocket.bind(('',9001)) |
如果是设计知名协议(http、smtp)的服务端,那就要使用这个协议指定的端口。
复用和分解
假设A主机有一个进程额UDP端口是10000,发送给B主机UDP端口为20000的进程,那么主机A的运输层首先创建一个运输层报文,包括数据,源端口,目标端口,传递给网络层,网络层封装到IP数据报中,向B主机发送。
到达B时,B的运输层检查目标端口,然后把数据交给该端口对应的套接字(定向分解)
注意事项
UDP套接字是一个二元组,包含了一个IP和端口,比如上面bind方法里面的参数
1 | ('',9001)# 第一个参数是IP,当为空时代表本机 |
源端口的作用,是服务端返回数据时用的
2.面向连接的复用和分解
TCP套接字使用了四元组(src_IP,src_prot,dst_IP,dst_port)标识,目标主机会使用四个值分解到相应的套接字。
使用python代码演示一下TCP
- TCP客户端创建套接字并连接上服务端
1 | clientSocket = socket(AF_INET, SOCK_STREAM) |
- 当服务端接收到请求后,定位服务器进程,然后建立一个新的套接字
1 | connectionSocket, addr = serverSocket.accept() |
- 此时服务端会注意连接请求报文的4个值,如果后续到达的报文段4个值与连接的4个值相等,则将数据分解到新建立的套接字上。这就算建立连接完成了。
- 前面说的持续HTTP就是使用同一个套接字传输数据,非持续就是不断产生新的套接字,这是比较浪费服务端性能的
端口的安全性
端口对于破坏者来说相当于突破口,如果该端口上的应用程序有缺陷,则破坏者就能在攻击的主机上执行任意代码,导致主机被攻陷。
3.3-UDP
UDP被称为是无连接的,因为发送方与接收方的运输层实体之间没有握手。
DNS通常就使用了UDP,因为TCP需要握手,如果使用TCP的话,DNS查询会慢很多,而UDP不需任何准备就可以传输数据
TCP是可靠的传输协议,那我们什么时候使用UDP呢。下面是比较适合使用UDP的几点
- 希望随时发送数据,可以容忍一点数据丢失,TCP有一个拥塞控制机制,当链路拥挤时会阻塞运输层的发送
- 不想建立连接,连接也是有往返时延的,如DNS使用UDP
- 分组首部占用小,UDP报文端有8字节的首部,TCP有20字节
因为UDP没有拥塞处理,所以会有较高的丢包率
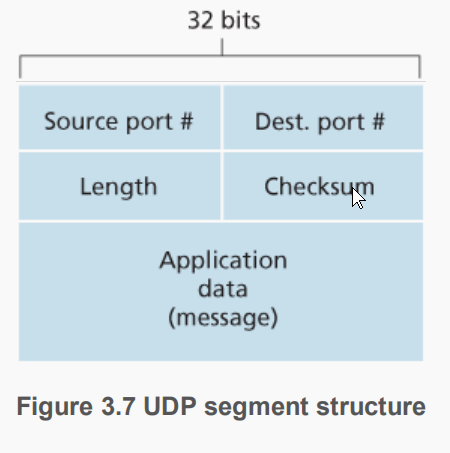
3.3.1-UDP报文段结构
应用层数据占用UDP的数据字段。UDP首部有4个字段,每个占2字节;除了源端口和目的端口,还有Length和校验和,Length表示报文段的字节数(首部+数据)
3.3.2-UDP校验和
为了确保数据在发送过程中不会出错,发送方的UDP会对报文中的所有16bit字节进行相加(溢出部分不管)再取反,将结果放在校验和字段,接收方将所有16bit全相加,如果结果不是1111 1111 1111 1111则代表出了差错
其实数据链路层也有差错控制,为什么UDP还需要呢?主要是因为不能保证源和目的之间所有链路都有差错控制,其次就是当报文传递到内存中也可能出现差错。
UDP也是可以进行可靠传输的,但这需要应用层开发人员建立一些机制,并大量调试
3.4-可靠数据传输原理
这章使用术语‘分组’,只考虑单向传输
3.4.1-从0构造一个可靠数据传输协议
书中从研究最简单的协议进行深入得到一个无错的、可靠的协议
可靠传输rdt1.0
在这个协议中,设定底层信道是完全可靠的。
下图是发送和接收方的有限状态机FSM(Finite-State Machine),FSM简单来说就是描述某一时刻的状态和转换状态字符
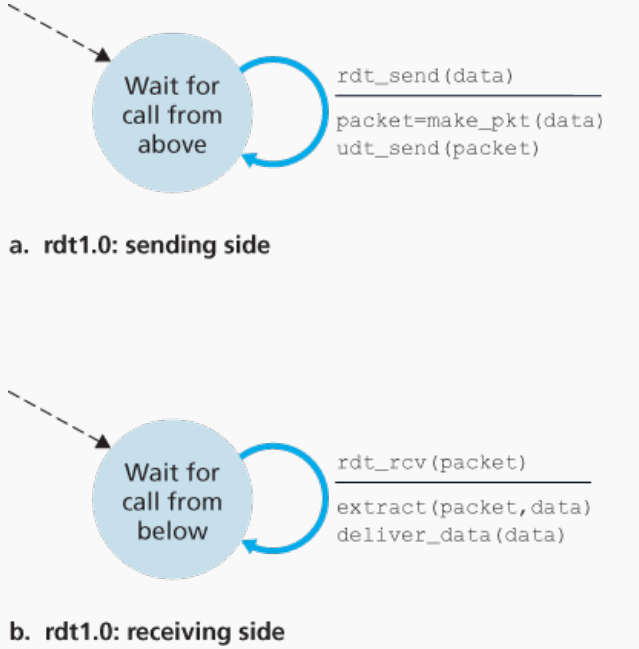
蓝色箭头代表状态的改变,这里的FSM只有一个状态。横线上方是事件,下方是动作。
假设发送速率和接收速率一样,又有完全可靠的信道,所以不用担心差错问题,和发送速率问题。
rdt2.0
这个协议考虑到了信道的差错。
类比人类,如果小明对小红说话,而小红没听清,于是叫小明再说一遍。
在rdt2.0里使用了自动重传请求ARQ(Automatic Repeat reQuest)
- 差错检测
- 接收方反馈:确认(ACK)和否定确认(NAK)
- 重传
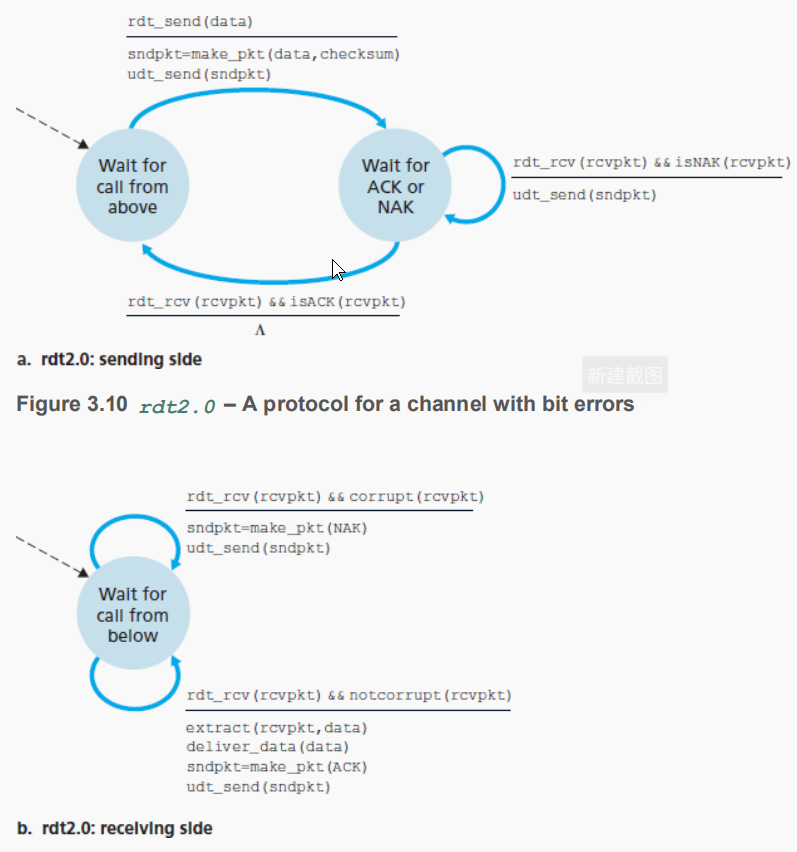
发送端比1.0增加了一个状态–等待接收方回答,由于发送端发送数据后就进入了等待状态,所以这种协议叫停等(stop and wait)协议。
而接收方就准备接收和回答。
这个模型的缺点就是当回答出现差错时,发送方就不知道接收方是否正确的接收到了数据
解放方法(书上还有重述和纠错,但介绍模型只有下面两个)
添加冗余ACK,出错就重传当前分组,缺点是不知道分组是最新的还是重传的
传输协议在数据分组中添加一个新字段,然后对数据分组编号,将序号放在这个字段。所以接收方会检查序号来选择是否重传。
对于停等协议,这个字段采用1bit记录。接收方根据最近的分组序号是否相同可以知道重传的分组,根据不同可以知道新分组。
rdt2.1
从上面的方法改进rdt2.0,这里假设信道不会丢失分组,而ACK和NAK也不用回答序号,因为我们知道是响应最近的分组
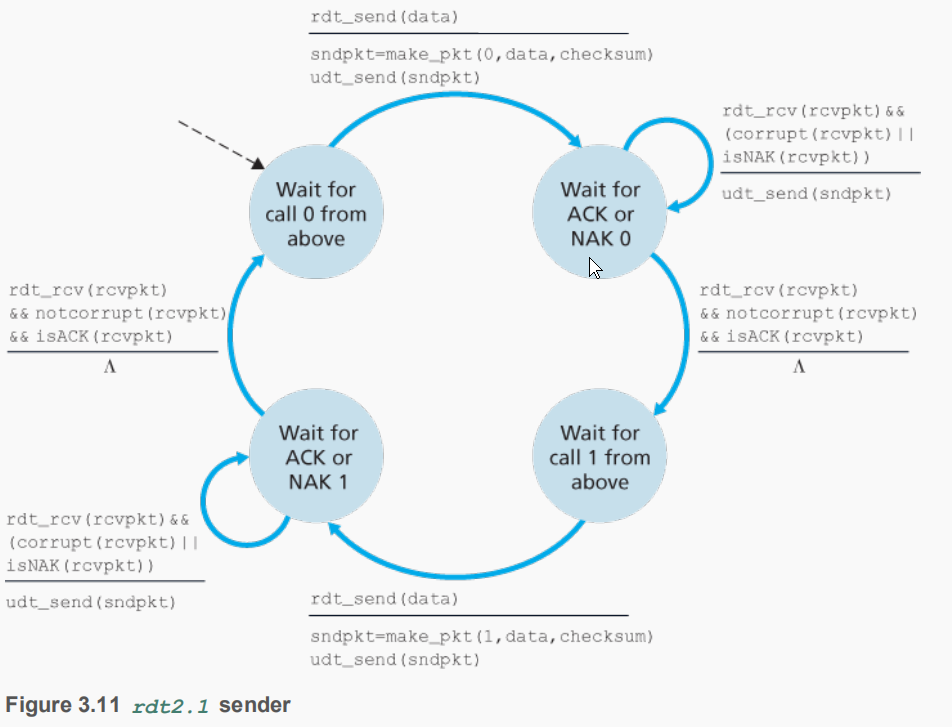
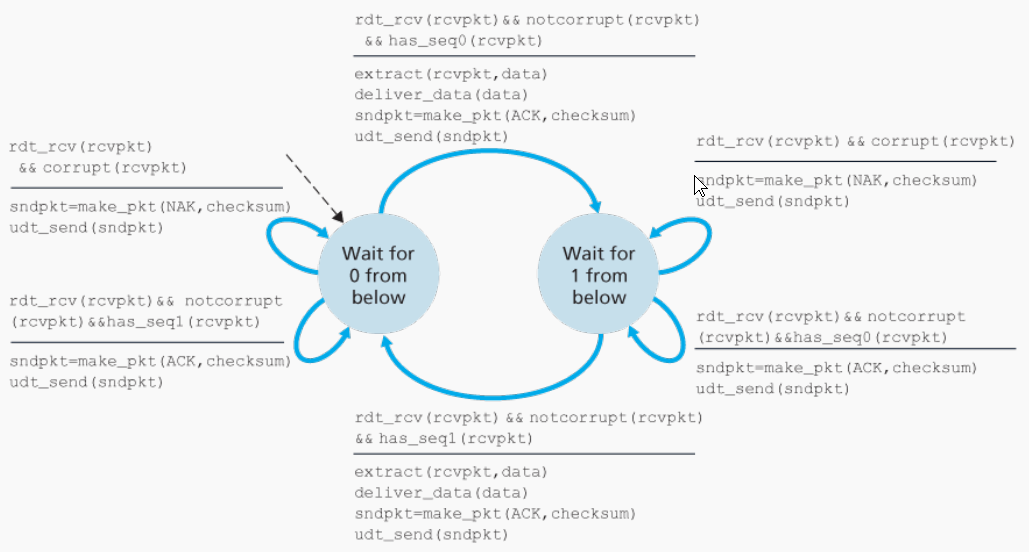
Λ代表无事件或动作
发送方依旧通过NAK和ACK接收回答,但如果接收到同一分组的两个ACK,就说明后面的分组没有收到。
rdt2.2
展示了一个有比特差错信道上实现的无NAK的可靠传输协议
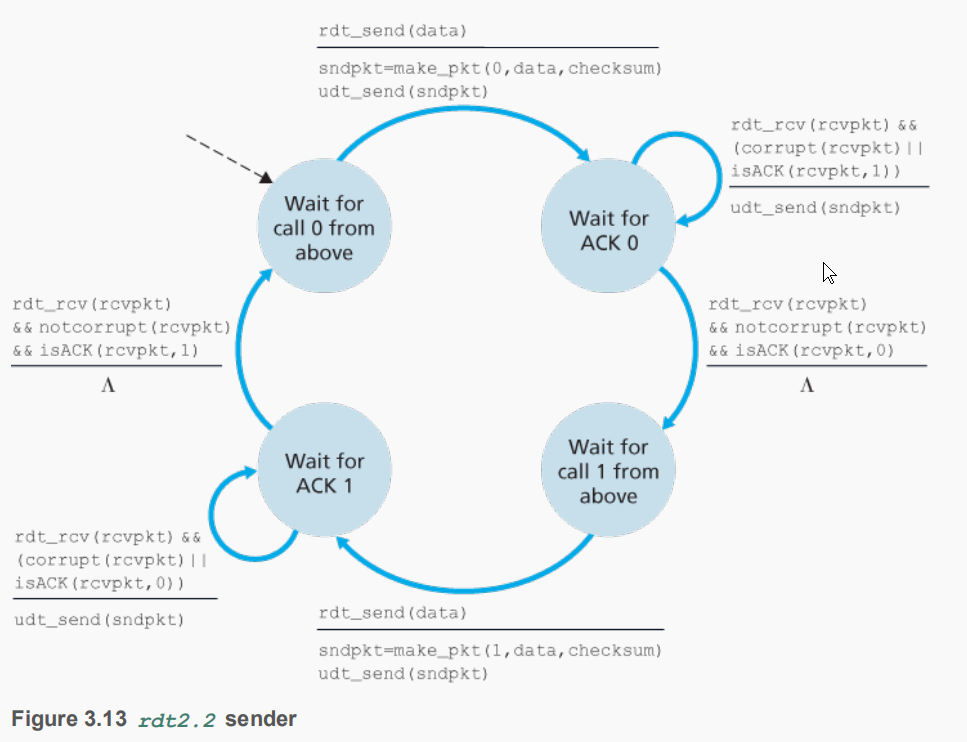
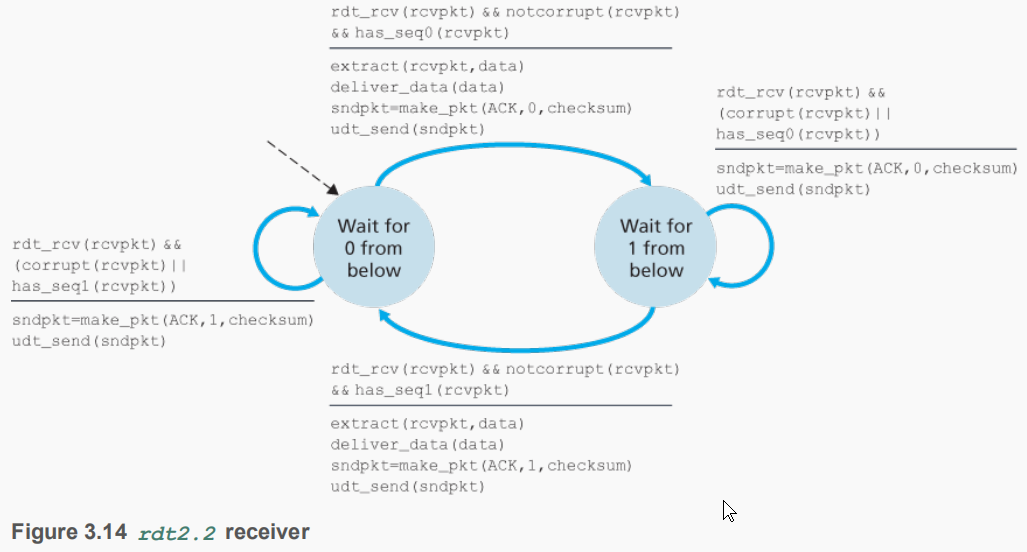
接收方与2.1的区别就是回答增加了分组序号,发送方需要检查这个序号来选择重传和发送下一个分组。
rdt3.0
前面考虑的都是bit差错,而网络上丢包屡见不鲜(比如你如果在大陆ping我的网址,绝对丢包,因为我的网站部署在github上,大陆在github的访问速度一言难尽),如果丢包,需要解决两个问题:1.如何检测丢包。2.如何处理丢包。第二个问题rdt2.2已经解决了,为了解决第一个问题,需要增加一个协议。
而判定一个数据包丢失的因素,最好的就是时间超时,发送方可以每发送数据分组时启动一个计时器,在规定时间过期后就可以重传。
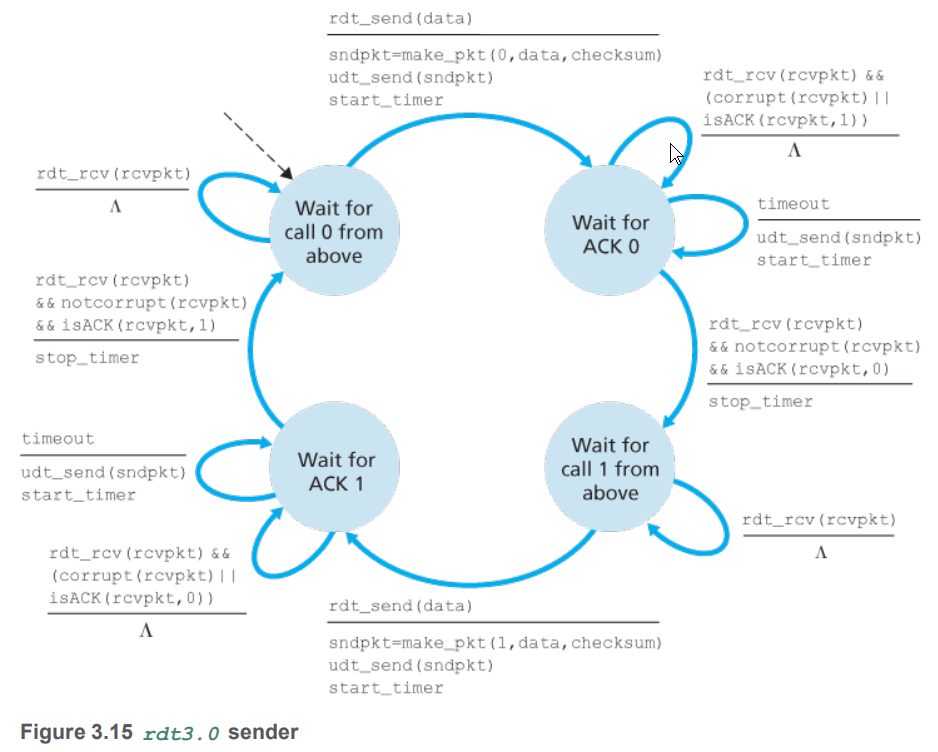
上面就是rdt3.0的发送方,运行大致步骤:
- 发送分组0,启动计时器
- 接收回应,如果分组出了差错,等待超时
- 超时后,重传,启动新的计时器
- 分组正确被接收,停止计时器
- 当ACK因超时到达时,do nothing
- 发送分组1….
下图就是当ACK超时到达时的运行情况
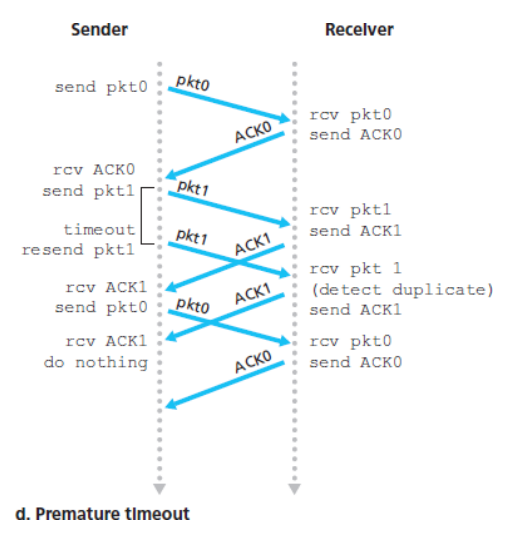
因为序号在0与1之间转换,所以rdt3.0也叫比特交替协议(alternating-bit protocol)
3.4.2-流水线可靠数据传输协议
停等协议有着很大的性能缺点,在1Gbps的链路,当往返传播时延(RTT)比较大时(几十毫秒),信道利用率只有万分之几(发送方传输时间与接收时间+RTT的比值),也就是说即便是1Gbps的链路,也只能达到kbps级别的吞吐量。这充分体现了网络协议可以限制硬件能力。
所以,有了流水线协议,它的特点就是一次发送多个分组,分组利用率就提高多少倍。
为了保证流水线协议的可靠性,必须保证以下几点
- 增加序号范围
- 增加缓存
- 处理分组丢失、损坏、延时过大等问题:如回退N,选择重传。
3.4.3-回退N步
GBN(Go-Back-N)允许发送多个分组,N代表未确认的分组不能超过N.

base代表已经发送等待回应的最初序号,nextseqnum代表下一个准备发送的序号,整体随着协议的运行有点像一个滑动的窗口,所有N被称为窗口长度,GBN也叫滑动窗口协议。
分组的序号是在首部的固定字段中,范围与所占bit有关。
下图就是GBN的发送方和接收方的FSM,包括了一些编程语言的特性–变量。
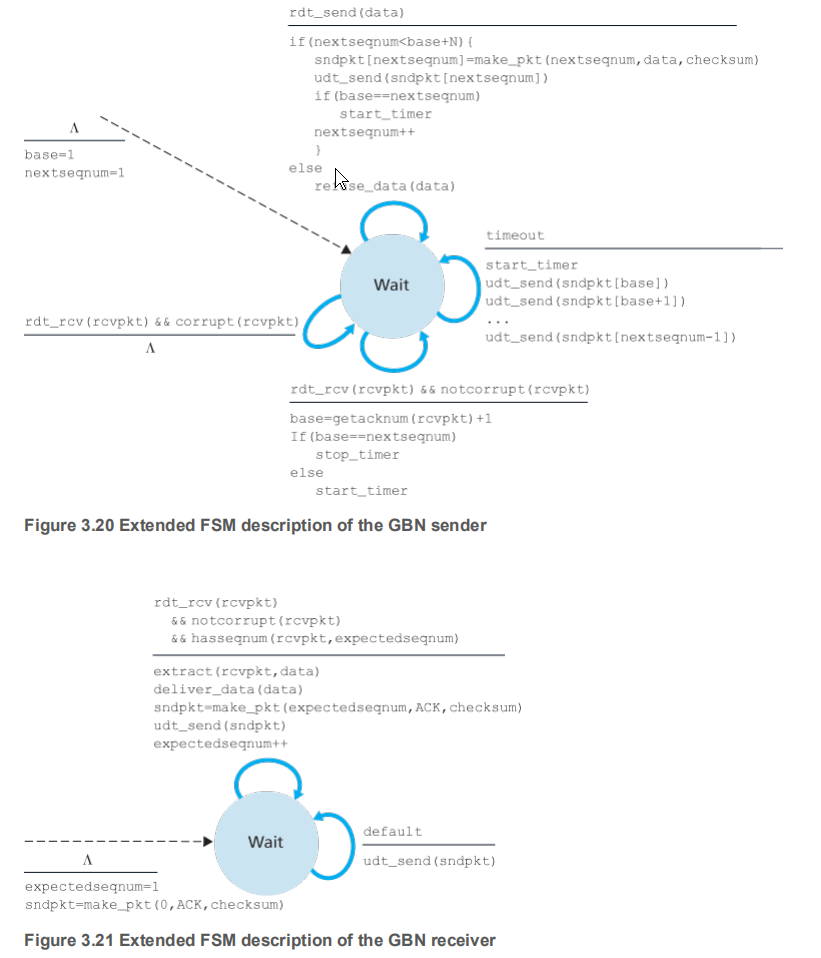
发送方
- 当窗口未满时,允许上层调用
rdt_send(),发送n(将窗口填满)个分组并启动一个计时器 - 接收ACK,因为接收方对ACK的要求,发送方接收到n序号的ACK,则代表n以前的分组已经顺利交付
- 超时事件,如果某个分组丢失或者超时,就会重传没有被确认的分组
接收方
- 如果是按序号到达的,则发送这个序号的ACK,并交付给上层
- 如果不是,则丢弃,并发送最近序号的ACK
我总结了GBN的特点
- 如果不是按序到达,则后面的分组会被接收方丢弃,由发送方重传
- 如果接收方前面所有的ACK丢失,哪怕最后只有一个ACK,发送方也会知道分组完好到达接收方
3.4.4-选择重传SR
GBN的缺点很明显,也是一个性能问题,当中间某个分组丢失,则后面的所有分组也会被丢弃。
选择重传就是将不按顺序到达的分组缓存并发送ACK,等前面分组齐了就交付。
发送方
- 从上层接收数据,如果序号在窗口内,则打包数据发送,否则不进行传输
- 超时,现在每个分组都有一个逻辑计时器,某个超时就发送某个分组
- 接收ACK,若ACK序号在窗口内,则标记该序号为已接受,如果==base,则窗口向前滑动
接收方
- 接收分组序号在窗口内,若前面有空的序号,则该分组缓存,并发送ACK;若该序号与后面的序号连续,则交付这串连续的分组,发送ACK,并滑动窗口
- 接收到以前确认的分组(不在窗口内),发送ACK
- 否则忽略掉
注意:SR的窗口长度必须<=序号空间(包括0),否则会因为不同步的问题难以区分新旧分组
总结
| 机制 | 用途 |
|---|---|
| 校验和 | 检测分组的bit错误 |
| 定时器 | 检测超时、丢包 |
| 序号 | 接收方判定重传的是副本还是新的 |
| ACK | 接收方告诉发送方”收到” |
| NAK | 和上面相反 |
| 窗口,流水线 | 窗口利用率低,流水线要好得多 |
3.5-TCP
TCP连接是带有状态的,初次连接会初始化这些状态变量。
TCP是全双工服务(full-duplex service),指的是点对点的交换数据,即一对主机。
建立一条TCP连接:客户先发送一个特殊的TCP报文段,服务接收后用另一条特殊的TCP报文段回应,客户发送第3段报文(含有上层数据),这种过程称为三次握手。
建立连接后双方可以互相发送数据了,数据向从套接字出发后,就交由TCP控制,TCP会先将数据放入缓存,时机一到就发送。从缓存取出封装发送的报文段受最大报文段长度MSS(Maximum Segment Size)影响,MSS由最大传输单元(链路层)MTU(Maximum Transmission Unit)设置。一般MTU都是1500字节,MSS都是1460字节,因为IP+TCP首部有40字节。
MSS指的是报文段里的数据长度,不包括TCP首部
官方TCP缓存示例
TCP的报文段结构
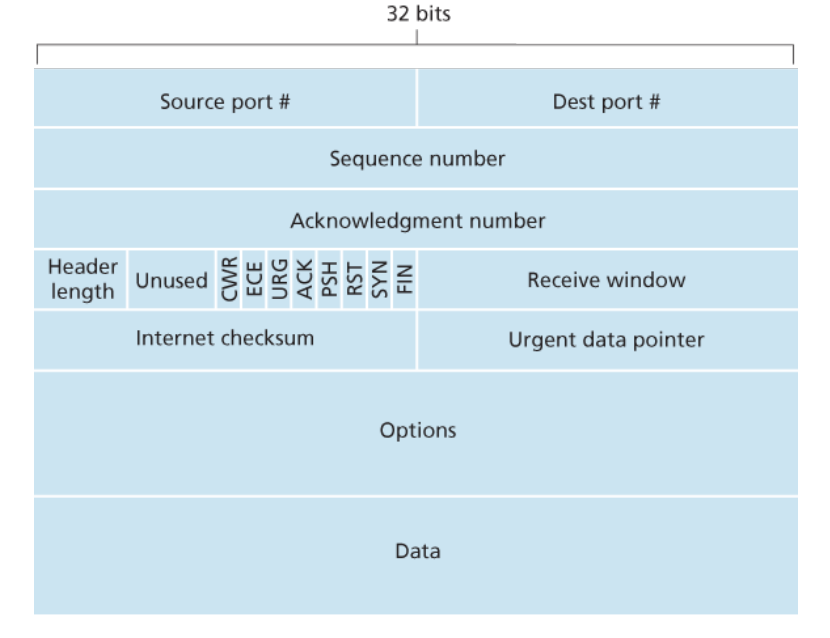
从上到下,左到右的简述
- 与UDP一样,开头是源端口和目的端口,每个16bit
- 第二和第三行是序号字段(Seq)和确认(ACK)字段,这是实现可靠数据传输的重要部分
- 4bit的代表首部长度字段,单位是32bit,可以代表0-60byte(15x32/8)。通常TCP是20字节,可选字段会影响这个长度
- 4bit未使用
- 8bit的标志字段,ACK标识上面的ACK字段是否有效,RST、SYN、FIN表示连接、建立、拆除;PSH代表接收方需要马上上交数据,URG代表存在紧急数据。
- 16bit的接收窗口字段
序号和确认
将数据流拆分成报文段,序号有利于将这些报文段正确重组成数据,即使他们无序到达。接收方发送的ACK里面是它期望的下一个报文段。(序号使用字节流编号)
假设1号到达,3号到达,而2号还在路上,此时1号期望2号,而3号也一样期望2号。这叫累计确认(cumulative ACK)。
对于提前到达的3号,RFC不提供规则,处理方法由开发者决定,要么丢弃,要么缓存。
实际上,防止旧连接的报文段与现有报文段冲突,初始序号都是随机的
我使用一段对话来帮助理解:
A表示客户,随机序号10,B表示服务端,随机序号20
- A:’你好,我是10号(Seq),携带5字节的数据,我期待20号(ACK)’
- B:’收到,我是20号,携带100字节,期望15(10+5)号’
- A:’收到,我是15号,我期望120号的数据….’
- ……..
接下来是一些关于估计往返时间(RTT)和设置重传时间间隔,有点看不懂,跳了
TCP可靠传输
为每个没有ACK的报文段使用计时器,不容易管理。采用的简单模型如下
发送方三个事件
- 接收上层数据:创建TCP报文段,如果当前无计时器则启动一个计时器,传递给IP封装发送
- 超时:发现计时器超时,重启,并发送超时的最小的序号段
- 接收ACK:将ACK序号与当前序号对比,如果大于,则当前序号=ACK序号;当前还有未确认的报文段,重启计时器
因为采用累计确认,所以ACK序号前面的字节都代表完好无损的到达了
需要注意的一点就是在传输数据时,如果第一个事件和第三个事件都没发生,超时每次重启的时间间隔都会是以前的两倍,这是为了缓解网络拥塞
这种重传机制也会增大时延,接受方也采用了一定的策略来解决这种不必要的时延
| 事件 | 接受方动作 |
|---|---|
| 当期望序号按序到达,且前面的序号都已确认 | 延时发送ACK,通常是500ms |
| 当期望序号按序到达,而前面还在延时发送ACK | 立即发送ACK,确认了两个序号 |
| 当报文段失序到达 | 发送最小确认序号的下一个期望序号ACK |
| 填充失序的中间序号到达 | 若是最小序号所期望的,则立即发送ACK |
而发送方接受ACK的动作增加了一项
- 连续接受到3个一样的ACK,则立刻重传丢失的报文段
流量控制
缓存毕竟有限,如果发送方不顾接受方是否愿意,强塞怎么办,那必然会导致接收方缓存溢出,而TCP报文段的接收窗口(receive window)字段可以控制发送方的发送速度,这就是TCP的流量控制服务。
请注意流量控制和拥塞控制之间的区别
TCP接收方的变量关系
- 最后一个从缓存读取的字节编号-最后接收进缓存的字节编号<=接收缓存
接收方需要发送的接收窗口大小就是上面两个编号的差。
TCP发送方的变量关系
- 最后发送的字节编号-最后一次接收的ACK编号<=接收窗口
注意:当接收方回应接收窗口为0时,发送方接收后还需要回应一字节的报文被接收方确认,当接收方缓存有空余时,确认报文的接收窗口不为0。
TCP连接管理
建立TCP连接:三次握手(three-way handshake)
- 客户端建立一个特殊的报文,将SYN同步序列编号(Synchronize Sequence Numbers)标志位设置为1,随机取得初始序号client_isn,然后发送
- 服务器收到后,响应SYN对该TCP分配缓存和变量,然后设置个SYN为1,ACK为client_isn+1,并取得随机序列号server_isn,然后发送SYNACK(如果一分钟之后没有回应,则关闭连接)
- 客户收到后,分配缓存和变量,然后设置SYN为0,ACK为server_isn+1,代表连接成功,然后发送带客户数据的报文段给服务器
断开连接
- 客户将发送一个将FIN标志为1的报文段,进入FIN_WAIT_1
- 服务器收到,然后回应ACK,客户收到进入FIN_WAIT_2
- 过一会,服务器发送FIN为1的报文段
- 客户端回应ACK,并进入TIME_WAIT状态,等待30s释放端口等资源
客户端经典的TCP状态图
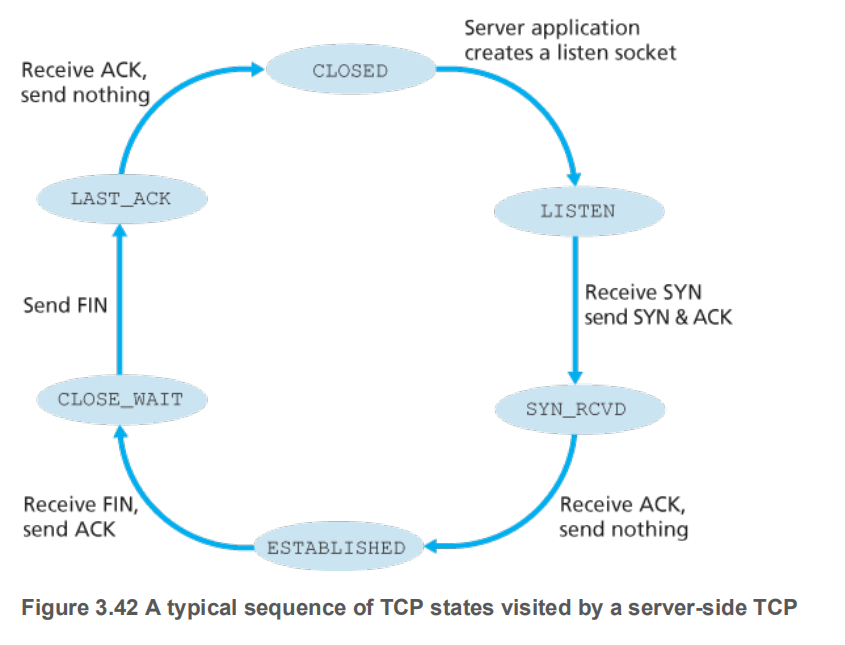
连接第三步后处于ESTABLISHED状态,可以发送有效数据
服务端经典TCP状态图
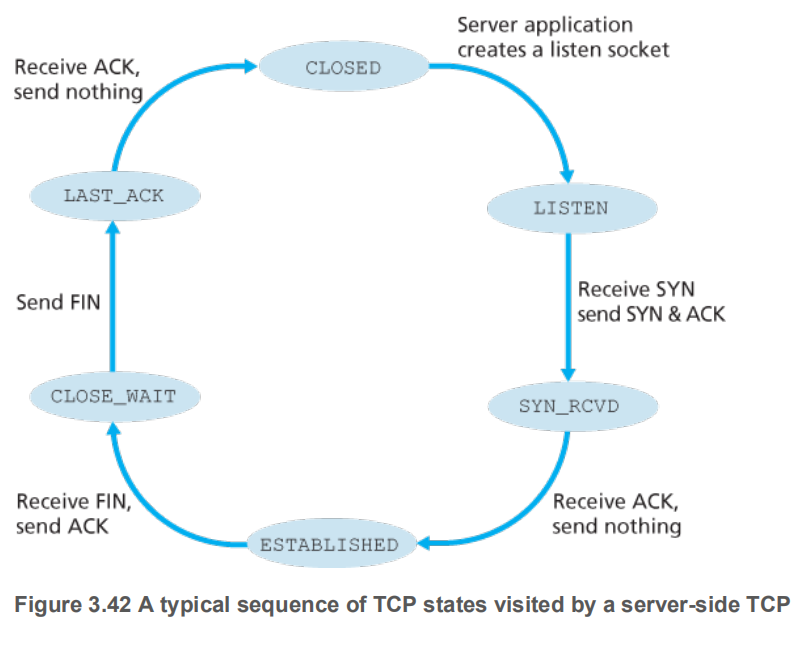
上图的服务端在监听,如果没有监听呢?服务会发送一个将RST标志为1的回应给客户端,含义是”套接字不存在,别发了”。
SYN flood attack
在三次握手中,第二步接到SYN分配缓存和变量,然后等待回应,一个针对这个漏洞的DoS攻击叫SYN洪泛攻击。
通过发送大量TCP SYN报文段导致服务器资源耗尽。
有个解决方案就是SYN cookie,在进行第二步时不分配资源;接收到SYN时,将客户IP,端口,和服务器的秘密数使用特殊函数生成一个初始序号发送SYNACK(不保存任何信息);当接收到回应时,将ACK和IP、端口,和服务器的秘密数生成的结果+1==它的ACK,则代表合法
nmap端口扫描器
可以得到任何服务器开放的端口,比如获取本机开放的端口
1 | ╰─ sudo nmap localhost -O |
原理
对目标主机的端口发送TCP SYN,得到输出
- 如果是TCP SYNACK,代表该端口打开
- 如果是TCP RST,代表端口没打开,同时也代表没有防火墙
- 什么也没有,代表有防火墙
nmap还可以得到UDP的端口,侦测防火墙,操作系统
3.6-拥塞控制
重传意味着分组丢失,间接代表网络拥塞。
控制方法
- 端到端拥塞控制:端系统通过关注时延和丢包来控制发送速率
- 网络辅助控制
- 路由器直接反馈发送方它的状态
- 接收方反馈网络状态
TCP拥塞控制
TCP采用的是端到端的拥塞控制,IP不会反馈网络拥塞。
发送端维护着一个变量叫拥塞窗口(congestion window),cwnd限制了发送端的发送速率。
$$
LastByteSent-LastByteAcked<=min(cwnd,rwnd)
$$
如果TCP觉得网络拥塞了,就会自动降低cwnd,网络通畅,增加cwnd。而TCP控制cwnd的原则有以下几点
- 报文段丢失,降低cwnd
- 丢包
- 得到4个一样的ACK
- 报文段正确到达,增加cwnd
拥塞控制算法
如何伸缩cwnd的细节
1.慢启动(slow-start)
cwnd初始值设置为MSS,得到ACK,则设置成2MSS,后面对每个ACK都会增加一个MSS,cwnd呈指数形式增长。
如果出现丢包,将变量ssthresh(慢启动阈值)设置为cwnd/2,cwnd设置为1MSS,继续上一步
当cwnd>=ssthresh时,结束慢启动转为拥塞避免状态
如果检测3个一样的ACK,则执行快速重传并进入快速回复状态
为了更高的响应速度,云服务器会采用TCP分岔技术
2.拥塞避免
- 每次RTT会让cwnd增加一个MSS,假设cwnd是MSS的十倍,则发送10报文,每个ACK会增加1/10的MSS(线性增长)
- 出现超时丢包,cwnd设为1,更新ssthresh为cwnd/2,进入慢启动
- 出现3个一样的ACK,ssthresh设为cwnd/2,cwnd设为ssthresh+3MSS,进入快速回复状态
3.快速回复
- 每得到丢失报文段的ACK,cwnd会增加一个MSS,然后进入拥塞避免状态
- 如果丢包,ssthresh设cwnd/2,cwnd设置为1MSS,进入慢启动状态
关于上面3个状态的FSM
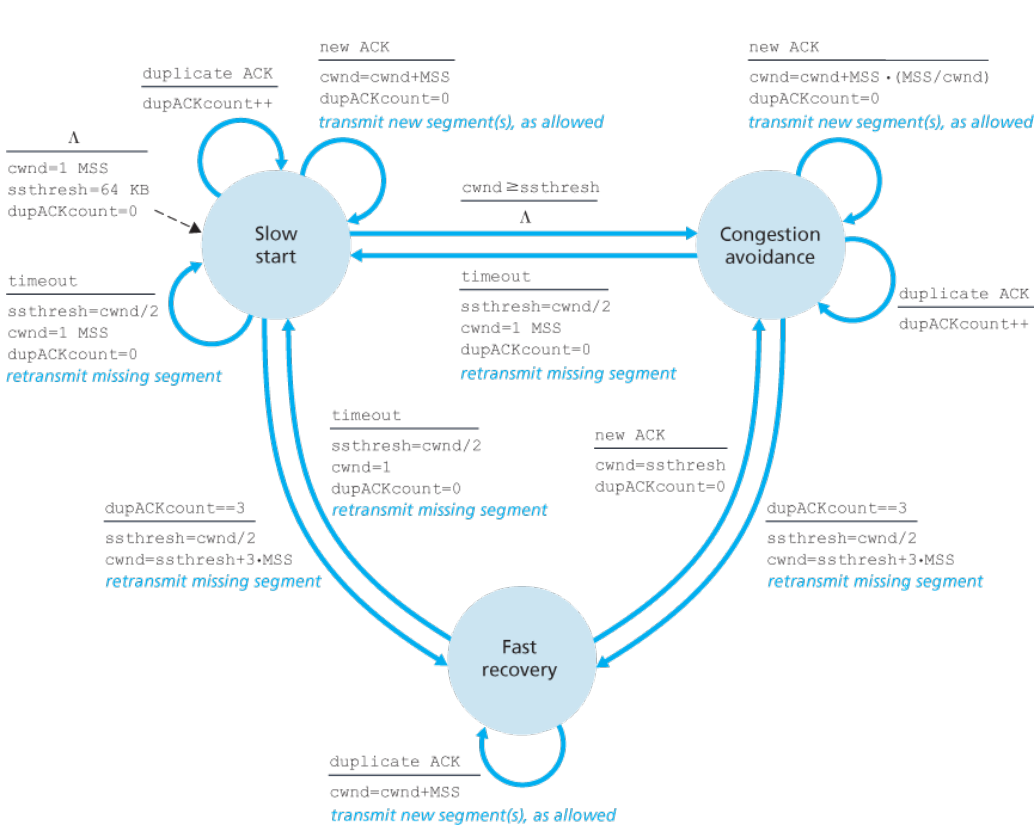
4.总结
如果是3次ACK的丢包事件,TCP的拥塞控制:每个RTT类线性增加1MSS,3次ACK将cwnd减半,因此TCP也叫AIMD(Additive-Increase,Multiplicative-Decrease)拥塞控制方式
5.TCP吞吐量
将丢包时的cwnd表示为W,对于一个稳定的精简的模型
$$
平均吞吐量=(0.75{\times}W)/RTT
$$
如果丢包率为L
$$
平均吞吐量=\frac{1.22{\times}MSS}{RTT\surd{L}}
$$
6.TCP和UDP的公平性
分析过程就不记笔记了,只记结果
用过拥塞窗口可以看到TCP是比较公平的,会根据拥塞程度适当调整速率,而UDP则是什么都不管,发送就直接发送,可以说UDP会压制链路上TCP的速率
书上说还是没有好的解决方案,而且就算UDP公平了,TCP的并行连接也是不公平的,他会分到更多的传输速率
3.7-显示拥塞通知(ECN)
Explicit Congestion Notification允许TCP发送方和接收方直接发送拥塞信号。
ECN在IP数据报头会有特殊设置位,路由器会根据拥塞情况改变该设置位,当接收主机收到拥塞指示时,将TCP首部标志位ECE(Explicit Congestion Notification Echo)打开,发送方接到该信息就会做出反映,然后在下一个报头设置CWR((Congestion Window Reduced)。
第三章总结
首先就是介绍运输层为应用层提供的服务,如UDP是一个很简单的协议,提供的服务也很简单,只传输,不可靠。而TCP提供了数据可靠交付,时延保证,带宽保证。
因为网络层是不可靠的,有从0开始完成一个在不可靠的层上面完成一个可靠的传输(ACK,重传,定时器等)
然后学习了TCP的连接管理、流量控制、可靠数据,研究了最初的TCP和升级TCP,以及它的拥塞控制
可以看到这两个协议还是不完美,新建立的标准的协议有DCCP、SCTP、TFRC等等,应用层度还有待取证
后记
一些数据分析对于我来说还是难点,希望自己学完高数后重温这些分析。